Well, I keep looking for bugs in portfolio_track.py – seeing as how it tells me I’m a genius stock picker.
I don’t trust programs that try to butter me up.
Especially those I write, myself.
But, unfortunately for my sense of peace, while fortunately for my wallet, those bugs just don’t seem to be easy to find.
Anyway, it got me thinking about converting the output of portfolio_track.py from what it tells: how you’re doing against a market average – to how you’re doing in percentiles of possible “market” investors. That is, if, say, 100 people dartboarded the market average’s stocks, how many of ’em would you do better than?
So, since God made computers to save us having to work for a living, let’s find out…
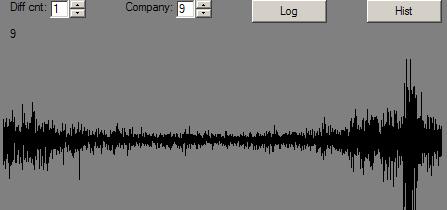
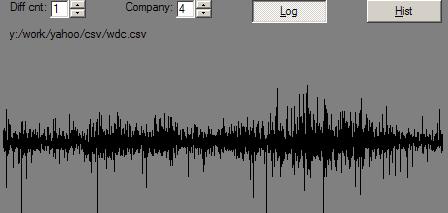
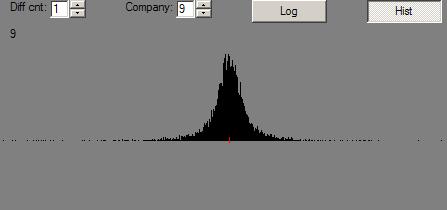
Let us, for instance, take an S&P 500 list of stocks (as of sometime late last year), and buy 15 of ’em at random a year ago. Then sell ’em today. Do that 100 times and tell us a distribution of the results:
From: 21-Apr-05
To: 21-Apr-06
Multiplier: 1.0
Percentile Distribution
1 5.5 5.5
2 9.7 9.7
5 12.9 12.9
10 15.4 15.4
15 18.3 18.3
20 19.7 19.7
30 21.9 21.9
40 22.9 22.9
50 25.6 25.6
60 27.8 27.8
70 30.5 30.5
80 34.4 34.4
85 36.1 36.1
90 38.1 38.1
95 40.1 40.1
97 43.1 43.1
98 44.7 44.7
99 47.5 47.5
To explain: the line, “98 44.7 44.7” tells us how the portfolio in the 98th percentile did. It gained 44.7%. His equivalent on the dunce side gained 9.7%. And, the average portfolio was up around 25%.
There are two percentages printed. The first is the second multiplied by the “Multiplier” – a factor that makes the first percentage normalized for a 1-year period.
Well, that’s all real cool, execept that the real S&P 500 was up about 13-14% over the same year. So, what’s the deal?
I can think of two reasons for why dartboarding some stocks from the S&P list was better than buying an index fund:
- Survivalship bias. The stock list doesn’t include dogs that were in the list a year ago, but which were dropped because they died or floundered.
- Weighting. The S&P 500 average is weighted. So, perhaps the stocks with high weights did less well than those with low weights. The dartboard picks randomly, so it’s relatively skewed by better stocks.
And, maybe both of these factors were the cause of the results.
I ran the script over a period of time last year when the S&P 500 dropped. March 7 through April 28th of last year. (The script is told next-day dates.)
From: 8-Mar-05
To: 29-Apr-05
Multiplier: 7.02485966319
Percentile Distribution
1 -86.6 -12.3
2 -83.9 -11.9
5 -76.7 -10.9
10 -70.5 -10.0
15 -68.2 -9.7
20 -65.3 -9.3
30 -60.6 -8.6
40 -57.8 -8.2
50 -52.7 -7.5
60 -48.3 -6.9
70 -41.8 -5.9
80 -37.6 -5.3
85 -32.7 -4.7
90 -29.7 -4.2
95 -25.8 -3.7
97 -24.7 -3.5
98 -21.3 -3.0
99 -12.9 -1.8
This is a closer match to the S&P 500’s average loss of the time, 6.7%, which is how a dartboard in the 6x percentile did. This helps the argument that dartboarding a market average has the effect of magnifying the swings. But, if that were so, then it seems like it would be possible to arbitrage the differences in volatility ‘tween a market average and a dartboard of the average. And, if that were the case, then that arbitrage opportunity would have long been taken (since it’s not exactly rocket science).
Anyway, here are the results from a run over a similar date period, but over which the real average was pretty much unchanged:
From: 3-Feb-05
To: 13-Apr-05
Multiplier: 5.29305135952
Percentile Distribution
1 -22.9 -4.3
2 -22.6 -4.3
5 -19.1 -3.6
10 -16.9 -3.2
15 -8.6 -1.6
20 -6.6 -1.2
30 -3.0 -0.6
40 -0.2 -0.0
50 1.1 0.2
60 5.4 1.0
70 9.0 1.7
80 13.3 2.5
85 14.2 2.7
90 16.3 3.1
95 21.0 4.0
97 22.2 4.2
98 23.8 4.5
99 32.3 6.1
Just to give a gut feel for how accurate the numbers are, let’s run that script again:
From: 3-Feb-05
To: 13-Apr-05
Multiplier: 5.29305135952
Percentile Distribution
1 -28.6% -5.4%
2 -28.2% -5.3%
5 -23.8% -4.5%
10 -15.2% -2.9%
15 -11.6% -2.2%
20 -10.8% -2.0%
30 -6.3% -1.2%
40 -1.5% -0.3%
50 2.8% 0.5%
60 5.0% 0.9%
70 8.4% 1.6%
80 11.7% 2.2%
85 16.5% 3.1%
90 21.2% 4.0%
95 22.8% 4.3%
97 27.1% 5.1%
98 27.4% 5.2%
99 32.2% 6.1%
OK. ‘Bout the same. So a hundred portforlios works ok over a fairly short period of time. Hmmm. Just for fun, let’s try 500 portfolios instead of 100:
From: 3-Feb-05
To: 13-Apr-05
Multiplier: 5.29305135952
Percentile Distribution
1 -35.9% -6.8%
2 -27.3% -5.2%
5 -20.2% -3.8%
10 -16.2% -3.1%
15 -13.3% -2.5%
20 -11.3% -2.1%
30 -6.6% -1.3%
40 -2.8% -0.5%
50 -0.0% -0.0%
60 4.0% 0.8%
70 8.0% 1.5%
80 11.7% 2.2%
85 14.6% 2.8%
90 18.1% 3.4%
95 23.4% 4.4%
97 25.4% 4.8%
98 27.5% 5.2%
99 33.1% 6.3%
Well, it might be a bit smoother and have better numbers out at the ends.
So, now let’s try 30 darts rather than 15 (you can see I’m improving the print-out with each run of this script):
From: 3-Feb-05
To: 13-Apr-05
Portfolio size: 15
Darts: 500
Multiplier: 5.29305135952
Percentile Distribution
1 -30.6% -5.8%
2 -24.0% -4.5%
5 -20.4% -3.8%
10 -16.0% -3.0%
15 -13.3% -2.5%
20 -9.8% -1.8%
30 -6.6% -1.2%
40 -2.9% -0.6%
50 0.2% 0.0%
60 3.1% 0.6%
70 6.6% 1.2%
80 11.0% 2.1%
85 13.4% 2.5%
90 16.8% 3.2%
95 22.4% 4.2%
97 25.4% 4.8%
98 27.3% 5.2%
99 31.2% 5.9%
Which, as one might expect, pulls the extremes in a bit, but doesn’t change anything else, really.
So, anyway, it would have been handy if I’d had a list of S&P stocks at the starting date. And, the historical data for each.
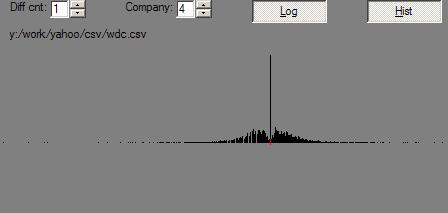
Off hand, I can’t think of a way to get portfolio_track.py to quickly print out what percentile of dartboard investors you’d be in. Since the width of the bell curve of those dartboarders is probably a function of the number of darts they throw, I guess that portfolio_track.py would simply need to use a formula that takes the number of stocks the real portfolio has in it.
Just to validate this thinking, here is another run with the dart count (the portfolio size) set to 400:
From: 6-Feb-06
To: 21-Apr-06
Portfolio size: 400
Darts: 500
Multiplier: 4.93521126761
Percentile 1-Year From-To Distribution
1 21.8% 4.4%
2 22.0% 4.5%
5 22.5% 4.6%
10 22.9% 4.6%
15 23.2% 4.7%
20 23.5% 4.8%
30 23.9% 4.8%
40 24.3% 4.9%
50 24.6% 5.0%
60 24.9% 5.0%
70 25.2% 5.1%
80 25.6% 5.2%
85 25.8% 5.2%
90 26.1% 5.3%
95 26.7% 5.4%
97 27.0% 5.5%
98 27.1% 5.5%
99 27.3% 5.5%
Anyway, I’ll run portfolio_track.py on the latest bunch of stocks I bought (which I haven’t felt particularly good about, and which weren’t bought in a single day, but we’ll ignore little dings which in this particular case make me look a hair better against the dartboard).
Symbol 1yrGain Market-relative
---------------------------------------
ALDA 89.8% 70.1% ~ ^GSPC
BBBY 41.4% 22.8% ~ ^GSPC
EGY 66.6% 43.7% ~ ^GSPC
FORD 10.7% -7.8% ~ ^GSPC
GTW -61.7% -80.2% ~ ^GSPC
JAKK 151.0% 132.5% ~ ^GSPC
KSWS -16.6% -35.1% ~ ^GSPC
MTEX 181.3% 162.8% ~ ^GSPC
OPTN 24.8% 6.3% ~ ^GSPC
WINS -61.6% -83.0% ~ ^GSPC
---------------------------------------
^GSPC 19.3%
---------------------------------------
Absolute: 42.0%
Relative: 22.7% ~ ^GSPC
Well, now, the S&P went up pretty good during that time. Let’s dartboard it, roughly:
From: 6-Feb-06
To: 21-Apr-06
Portfolio size: 10
Darts: 2000
Multiplier: 4.93521126761
Percentile Distribution
1 -20.1% -4.1%
2 -12.1% -2.4%
5 -1.6% -0.3%
10 4.2% 0.9%
15 8.9% 1.8%
20 11.3% 2.3%
30 16.2% 3.3%
40 20.0% 4.1%
50 23.6% 4.8%
60 27.5% 5.6%
70 31.5% 6.4%
80 36.0% 7.3%
85 39.2% 7.9%
90 43.3% 8.8%
95 51.6% 10.5%
97 58.6% 11.9%
98 66.4% 13.4%
99 84.7% 17.2%
Apparently, to feel good, I gotta get deep in the 90’s. 🙂
Which gets in to another subject – can the scientific method be used internally between selves? In fact, is it? … ‘Nother time. …
All this wandering makes something rather clear: If you’re investing in a market average, you’re effectively saying:
- you believe you are somewhere under the 50th to 60th percentile of investers (assuming that the difference ‘tween results of a 50 percentile investor and a 60 is not worth the effort).
- you don’t know where you stand in the percentiles – and want to assume that you’re as likely to be on the bottom as on the top.
- you figure that you are all over the map, depending upon time and circumstance
- there is no percentile ranking of investors. Everyone is the same.
Let’s assume that there is a ranking. How do you find your current position?
If picking stocks took no time and transactions were free, then it would make sense to dartboard a boatload of stocks (say 1 share each). Then, if you find yourself above the 60th percentile, start exchanging the stocks you most dislike for the ones you most like. Do that until you drop significantly in the rankings. That’s when you’ve reached your Peter-Principle level of incompetence.
Alternative that doesn’t require infinite time and free transactions: Buy a few shares of one stock and a lot of a market average “stock”. When you go above the 60th percentile with your picked stock(s), sell the market-average and buy a picked stock. Hill-climb the results of your total portfolio as you would using the previous method.
The hill-climb method you would use, by the way, seems to be identical to a method you would use to trim a boat with no tell-tales or instruments while sailing up-wind in shifting winds.