Here is another movie generated by my Kinsa fever data display program.
This video uses color to show which US counties have similar Kinsa fever thermometer statistics. This particular video colors counties with recent (previous 15 days) higher-than-other-county-fever-percentages in red tones, less recent high percentages in green tones, and high percentages older than 45 days in blue.
Watch red to see how fever moves around the country over time. Watch for blue to see counties that have had fever, but not for a while. Green counties were feverish around a month before the end date.
During the video, the end date runs from mid-March to August 7th.
This Corona Virus thing is, ignoring dead people, a lot of fun.
Why?
Well, because it’s so interesting. The progression of the disease is interesting, the reactions to the disease are interesting, and speculations about the post-virus future are interesting.
One interesting thing is the quantity of blather from the babble-world. Where are exceptions to misstatements, lies, confusion, and overall silliness?
One exception seems to be a company named Kinsa. They sell an Internet connected fever thermometer. $30 and $50. Currently sold out.
But, talk about perfect timing: Kinsa has data for much of the US showing when people were, and are, running fevers. Their data correlates pretty closely to flu season.
So, come Covid19, they moved fast and created https://healthweather.us. This web page shows in color and graphically which counties in the US have been affected by fevers and when, post February 16th.
The good, the bad, the ugly:
The Good: A couple minutes in the Firefox Web Developer says the data underneath the web page is remarkably clean and accessible. (OK, they’ve made breaking changes to the data a couple times in the last few days, but life is tough. Boo. Hoo.)
The Bad: Starting Feb 16? Why not Nov 1, 2019? I know why. But why?
The Ugly: Sorry, Tuco. You’re written out of this script. It’s a pretty web page.
Can the web page and data reveal outbreaks of fever in near real time? Kinsa sure hopes so.
As it turns out, the famously big US Covid19 outbreak (NY city) does show up in Kinsa’s data.
But, it remains to be seen what happens over the next few weeks as people wander out of stay-at-home. Thermometers don’t inherently pay attention to political spin, and don’t inherently serve to confuse. So, I’m rooting for Kinsa.
Now, this is all very nice, but what does it lead to?
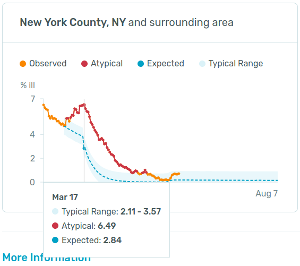
Well, look at the orange/red line in the NY County image above. Notice its shape – its profile. Call that shape the “fever profile”.
I was clicking around some counties on the web page and noticed an odd thing: Most counties had a fever profile from February to May that looked like neighboring counties. Like, say, county A had a spike of fevers around March 17th, and so did bordering counties B and C. Not counties two states over, though.
Fair enough.
But, sometimes there seemed to be sharp transitions between one county and the next with respect to their curves. Maybe my imagination. Maybe not.
I wanted to see the whole country’s county-time fever profile similarities at a glance. If two counties had a similar fever profile/curve from February through today, the two counties should look similar in a picture. And if their fever profiles were different, they should look different.
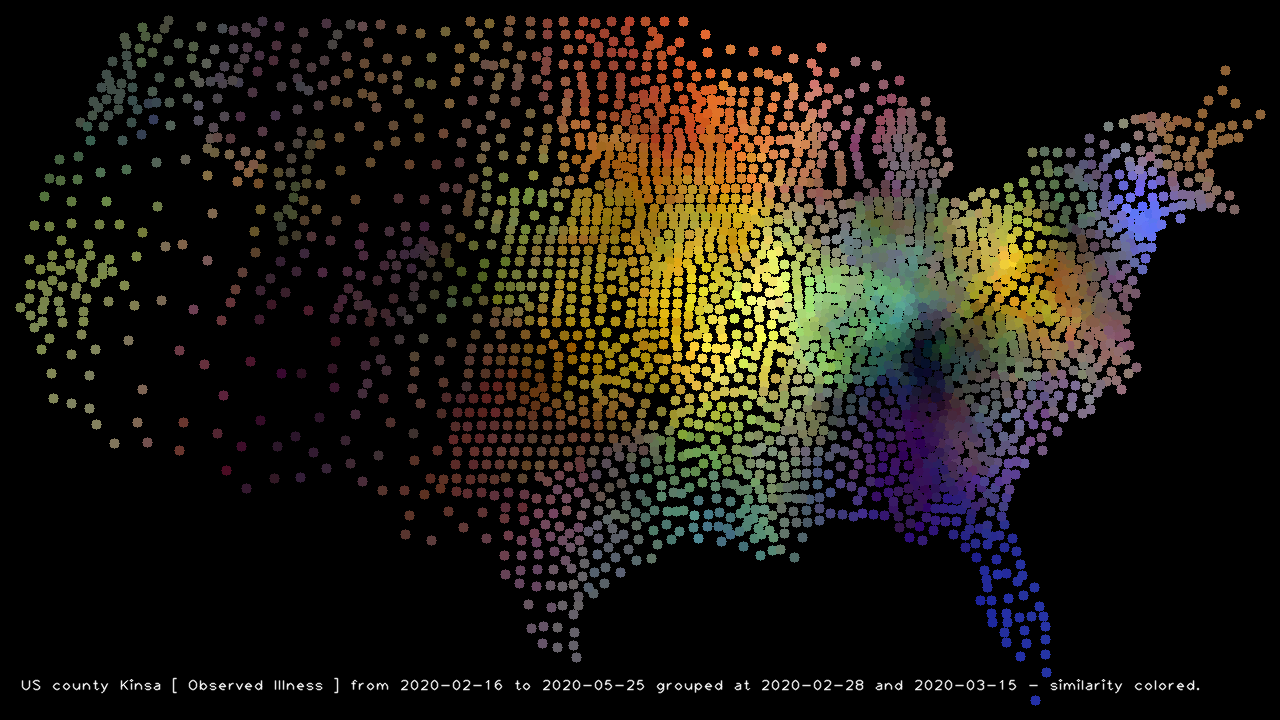
So, I whipped up a program to color counties based on the total fever-percentage-of-people numbers in 3 bands of time. E.g. Feb 16 to the end of February. The first half of March. And the third band for mid-March to the present. Then the larger the totals a county has in fever percentages in each band, the brighter a color is. The first band is red. The second, green. And the last, blue.
And, here is a picture of the US with counties colored based on fever percentage profiles as of today:
It looks like if you really didn’t want a fever, you should have been in a dark area – Arizona, New Mexico, or the Knoxville Tennessee area. That latter area is quite the surprise.
And if you like Covid19, you wanted to be in the bright blue (mid-March and later) Florida or the New York City areas. Don’t forget to be old!
If you want the flu (in red February), go north-central (ND, WI, MN, northern MI, … or … Canada?).
If you do like your body hot, go to where the colors are bright: downstate Illinois, Indiana, western Kentucky, and Missouri. Maybe Ohio. Or maybe California! Though in California a hot body could be taken two ways.
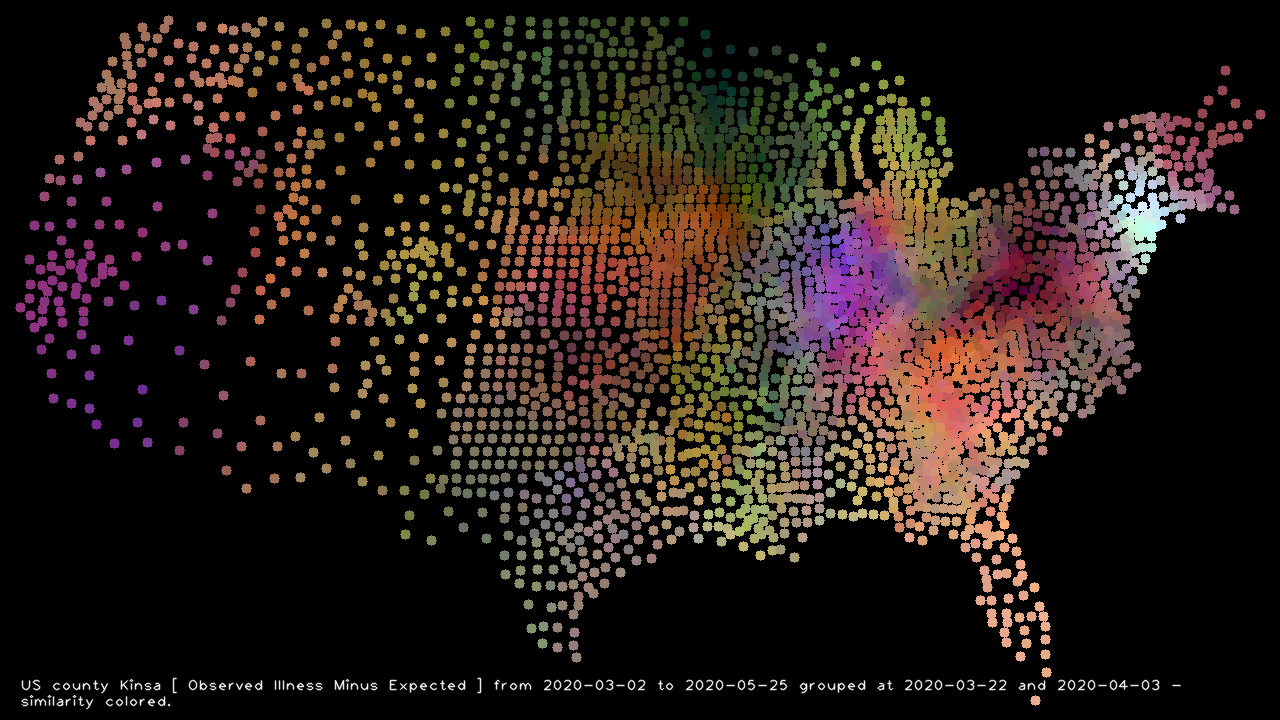
Here is a picture based on the fever percentages minus what Kinsaexpected them to be given historical trends:
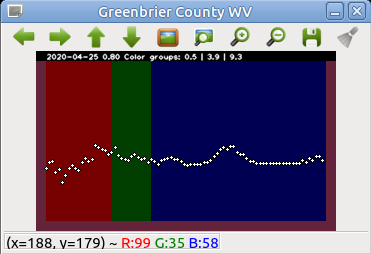
Bright New York is pretty clearly where the unusual fever has been. And I love the West Virginia hole in the picture. Examining the (Fever – Expected) profile for a county there:
shows they dodged the flu.
Another bright spot I didn’t expect was downstate Illinois. The bright purple says they probably had a bit more flu and Covid19 than Kinsa‘s expectations. Or something.
You want movies? You got ’em:
Percentages of people running a fever stepping “today” from February through May:
All in all, it’s been a fun program to write. It shows the fever profile of the county your mouse hovers over so you can quickly see the profiles of lots of counties in a geographical area. I’ve found that handy and kinda informative.
Starting with thoughts of how it would be nice to have a back and forth translator when writing an email to someone who speaks a different language…
You would normally write the email in your language, then crank it through a web translator to get the text for the other person.
Well, shouldn’t the translator show the text translated back from the target language to yours so you can check what the other guy will be reading?
Oddly enough, I didn’t find anything on the web to do that as you type. Weird.
But, then it gets interesting.
The guys developing translation software could use instances of people’s starting text and final text when people process their writings through a back-and-forth-erizer. Figure a person starts by saying what he wants to say in his language. Then, as he modifies what he writes so the translation is better, he’s effectively spelling out a way to translate from his language to his language. He’s showing you a meaning thesaurus, not just simple word substitutions.
(Gunning) Fog index: Wouldn’t the difflib comparison score between the original and the back-translated text be in some way consistent with fog indices? The translation software builders probably use something like this to evaluate their software. I would.
Certain pairs of languages will translate back and forth better than other pairs. What does that mean?
The translation software is better for those two lingoes?
The cultures/people are closer?
What else?
Over time, what happens? Can the changes in the pair distances be used as a metric of how the world is becoming a global village? Can such changes be used in any way to understand cultural differences? Can translation software improvements be normalized out of the pair distances over time?
Presumably, the translation software guys are monitoring the pair distances between languages so that there are no instances of translations being better going through an intermediate language rather than going direct from one language to another. If such were ever the case then the thing to do would be to train the direct translator using the longer route translations. Doing such a process iteratively sounds like a pretty good way to bring a new language in to the system. All the new language needs is a corpus of translations from it to one other language. Of course, this wouldn’t be a binary thing. The more effective pair-corpus’s would be able to bootstrap the less effective links, generally.
What are the implications of a world where people write using a language back-and-forth de-fogger? Does the writing end up bureaucratic? No personality. No sharp meaning. Vanilla.
Should textbooks be run through such a de-fogger? Should speeches? Especially in the education field, it seems important to get things across clearly.
Could using these back-and-forth techniques be used to build a new language? A better language? Could they be used to build a creole language?
If a language translation system built a creole language that’s close to an existing one, does that imply that the translation system understands the ingredient languages like a human?
Given net-available text, how much CPU does it take to build an effective language translation system?
Could back-and-forth translations be used to help translate old text in to modern language? That is, keep modifying the old text until you get the best back-and-forth for your modified text. It would be interesting to automate this whole process. Proof reader, editor, re-writer system.
Good URL, but probably going away in December (returns JSON translation of the ‘q’ string):
Years ago, I daydreamed about a head’s up display for futuristic Instant Messaging. The display would show vital signs of the “buddy” you were monitoring. Such an intimate thing might help with communication.
Viewing this waveform from the CMS50E requires an HTML5-capable browser (Firefox / Safari / Modern phones / Webit / maybe IE9). I do not know how timely the waveform will show up from outside the house. It updates on localhost about once a second – roughly in time with the heartbeat beeping from the device.
The waveform just stays put if the “finger” is out. Who knows what will happen when the device is not connected to the PC that runs the server.
The “finger” is my left index toe.
The project got a little out of hand. The general idea is to have a generic server that makes it easy to stream line/point numbers out to arbitrary numbers of web clients to graph. I cut things short to get this thing on line.
Some kind of tiny, packable, cot thingee that can convert an uncomfortable airport seat in to a usable bed that “watches” your things.
A wearable display to replace netbook/laptop/phone screens. The visual equivalent of an earbud, smaller and more robust than a normal screen, but with higher resolution.
Being away from the dual 1900×1280 screens is unpleasant.
And it would be pleasant to get some real sleep pending a flight on Godot Airlines.
Spent the last few days exposing to the net some of the odd-ball GPS logic I’ve done for my own amusement in the last year.
Specifically, TellAboutWhere fronts for the alternate route finder, sparsifying, hikifying, and bikifying logic.
More to come, probably. For instance, I’ll probably expose distance measurement, which, if I recall, simply adds up the tracks’ distance between points after the tracks have been sparsified.
Under the hood, TellAboutWhere is kinda cool. The web page CGI script doesn’t do much. It just writes out the uploaded files to a data directory and keeps track of the “file sets” in Python pickle files.
A (soon to be cron started, screened) script runs on “spring” against the uploaded GPS files on the server, “asuka”. Other instances of this background processing script could run on other machines if there were ever any significant traffic to TellAboutWhere. The processing script simply looks at input file names and insures that the various processed, output files exist for them. If a particular logical process doesn’t create any track data – say, hikify finds no hikes in a track – then the processing script creates a zero-length output file as a place-marker so that the logic isn’t done again.
“File sets” are groups of files. File sets make it easy to combine tracks together for alternate route finding.
For alternate route finding purposes, files in a file set may be checked/included or not.
TellAboutWhere keeps itself from being overloaded by only allowing 8 files in a file set. If you upload more than 8 files, TellAboutWhere whacks, first, files that are unchecked, then files at random. Since the input files are stored by (CRC32) hash, duplicate files are automatically eliminated.
It was time to scan the B2 todo.doc idea file (hashes of which are published to alt.security.keydist for lack of a better, public place to dump ’em).
One of the odd items in B2 was a note of curiosity about what words would change in the future. Specifically, what words would be shortened because they are used a lot? And what words would drop out of use because they are too short for their own good? I speculated that words that are too short are pompous, fuddy-duddy words, scheduled to go out of use, and words that are too long are hip-happening words, scheduled to be replaced by shortened forms of the word (“something” becomes “sum’em”, “about” becomes “bout”, “OK” becomes “K”).
The thing is, words that are in common use are short, e.g. “I the you me”. And rare words are usually big words. That makes sense. Huffman type compression is a natural phenomenon.
There are lots of word list out there. I turned to Wiktionary’s TV script word frequency list.
And, from a while back, I just happened to have a copy of all the audio word recordings from Merriam Webster.
Now, the durations of these recordings are not a very good indication of the duration of the words, but it’s a start. (I considered using a phoneme count from Wiktionary’s pronunciation guides)
If you sort the words by word-count and give them each an index corresponding to where they are in the list, and do the same for durations, you should be able to figure out which words have very different indices/rankings in the two sorted lists.
The sorted, absolute-value results should order the words in “stability”. That is, the words at the top of the list should either be too-short words, or too-long words.
class a_word(object) :
def __init__(me, word, cnt, dur) :
me.word = word # the word
me.cnt = cnt # the word's use count
me.dur = dur # the word's shortest .wav file byte length
me.cnti = 0 # the normalized ranking of the count (low rank are frequent words)
me.duri = 0 # the normalized ranking of the duration (low ranks are short words)
me.off = 0.0 # how far off the two rankings are
pass # a_word
#
#
if __name__ == '__main__' :
import os
import re
import sys
import time
import TZCommandLineAtFile
import tzlib
sys.argv.pop(0)
TZCommandLineAtFile.expand_at_sign_command_line_files(sys.argv)
wc_fn = sys.argv.pop(0)
wcs = tzlib.read_whole_text_file(wc_fn) # lines of: "word count (wav_size (...))" - we use the shortest .wav size
wa = re.split(r"\n", wcs)
wa = [ wc for wc in [ re.split(r"\s+", ln) for ln in wa ] if (len(wc) >= 3) and (wc[0][0] != ';') ]
words = []
for wc in wa :
wc[1] = int(wc[1])
words.append(a_word(wc[0], wc[1], min([ int(ln) for ln in wc[2:]])))
words.sort(lambda a, b : cmp(b.cnt, a.cnt))
i = 0
j = 0
icnt = 0
ucnt = 0
for w in words :
if icnt != w.cnt :
icnt = w.cnt
i = j
ucnt += 1
w.cnti = i
j += 1
icnt = float(i)
words.sort(lambda a, b : cmp(a.dur, b.dur))
i = 0
j = 0
idur = 0
udur = 0
for w in words :
if idur != w.dur :
idur = w.dur
i = j
udur += 1
w.duri = i
j += 1
idur = float(i)
for w in words :
w.off = (w.cnti / icnt) - (w.duri / idur)
words.sort(lambda a, b : cmp(abs(b.off), abs(a.off)))
print "; " + time.asctime()
print "; counts=%i durations=%i unique_counts=%i unique_durations=%i" % ( int(icnt), int(idur), int(ucnt), int(udur) )
print
print "; %-30s count cnti dur duri offness" % "Word"
print
for w in words :
print " %-30s %8u %5u %6i %5u %8.5f" % ( w.word, w.cnt, w.cnti, w.dur, w.duri, w.off )
print
print ";"
print "; eof"
Talking on the phone recently, it seemed like a good time to note down somewhere the EasySay characters I used for OnlyMe admin passwords and such.
EasySay characters are characters that are quite unambiguous / distinct both in spoken form and in written form.
In short, they are: “AESINO267”.
OnlyMe considered the other characters to be equivalent to their EasySay peers.
Granted, mapping from the other characters to the EasySay characters is ambiguous. Z? Good arguments could be made for it to map to E, 2, or S.
Here’s the table:
A ahjk8
E bcdegptvz3
S fsx
I ily159
N mn
O oqr04
2 uw
6
7
So, if the world used a 9 character alphabet we’d spend a lot less time on the phone talking like we’re WWII combat guys with huge radios glued to our ears.
Here’s an idea for a science fiction story: Somebody finds out that some part of the world has been created using a known random number generator. A predictable generator, that is.
Harkening back to a previous post, for instance, let’s say that someone notices that a simple program using a standard modulo-multiplication random number generator can create an almost exact profile of the Rocky Mountains, looking west from the Great Plains.
This must have been done already in plenty of ways, though I’d not know, not having read much sci-fi in a long time.